
Products
GG网络技术分享 2025-03-18 16:14 75
练习用文本引用网址: 举报投诉电话邮箱大全 中央国务院各部委举报投诉电话邮箱国家信访局网站信访指南http: www gjxfj gov cn xfzn htm中华人民共和国中央人民政府网 http: www gov cn中共中央办公厅、国 https://www.pinlue.com/article/2018/09/0805/336985678418.html
正则表达式测试网址: 在线正则表达式测试 OSCHINA.NET在线工具,ostools为开发设计人员提供在线工具,提供jsbin在线 CSS、JS 调试,在线 Java API文档,在线 PHP API文档,在线 Node.js API文档,Less CSS编译器,MarkDown编译器等其他在线工具 
import pypercliptext = str(pyperclip.paste()) # 将最近一次复制的内容转换为字符串
import re
regex = re.compile('(\\d{3}-)?\\d{8}(\\d{3}-)?')
mol = regex.findall(text)
print(mol)
正则表达式【(\\d{3}-)?\\d{8}(\\d{3}-)?】在网上测试正常,写入代码返回结果异常。
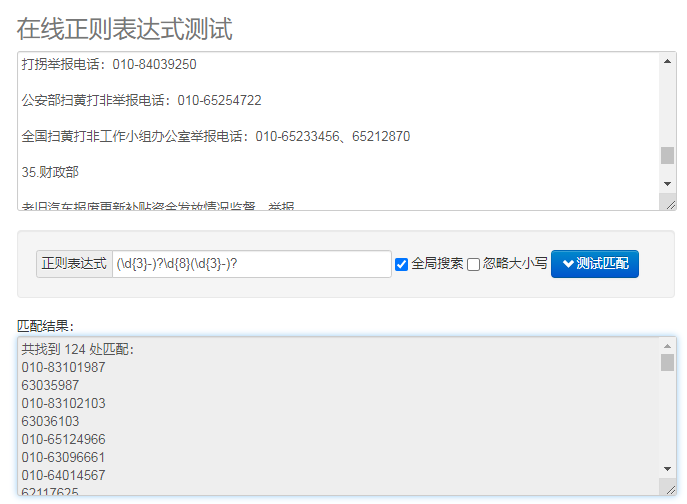
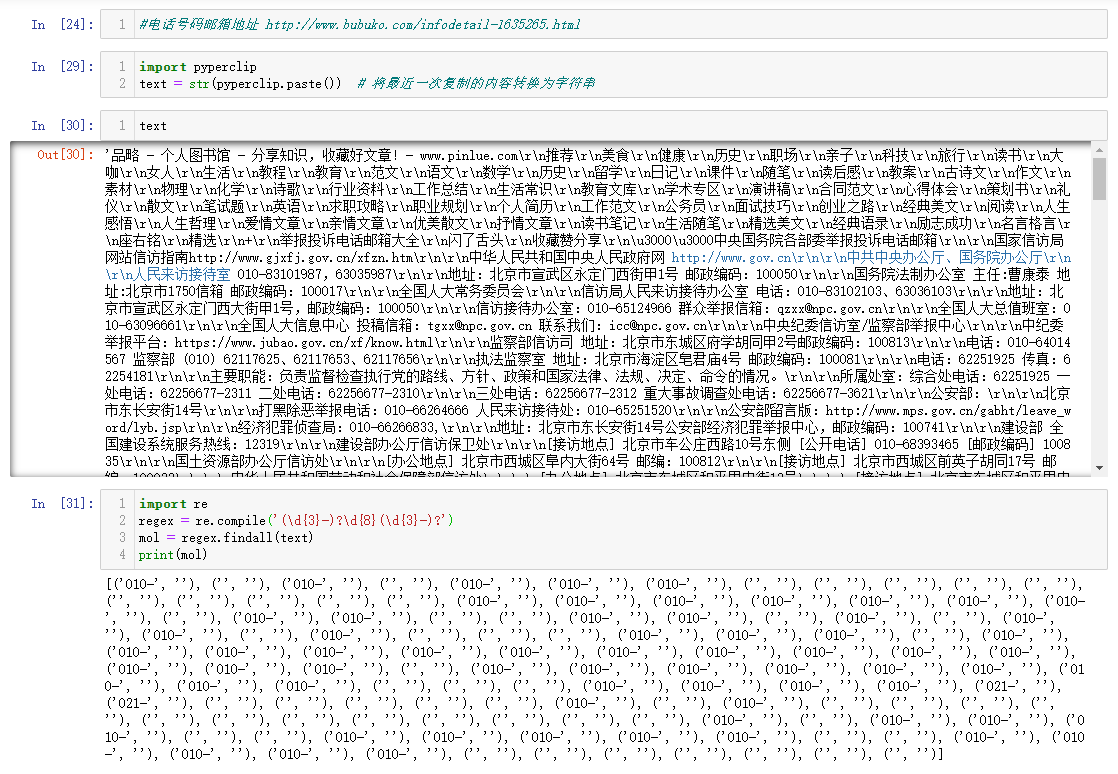
想匹配出带有区号或无区号的所有电话格式,请问如何修改
import pyperclip
text = str(pyperclip.paste()) # 将最近一次复制的内容转换为字符串
import re
regex = re.compile('(?:\\d{3}-)?\\d{8}(?:-\\d{3,4})?')
mol = regex.findall(text)
print(mol)
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式。
re 模块使 Python 语言拥有全部的正则表达式功能。
本章节主要介绍Python中常用的正则表达式模式与实例。
模式字符串使用特殊的语法来表示一个正则表达式:
字母和数字表示他们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
多数字母和数字前加一个反斜杠时会拥有不同的含义。
标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
"^d" 代表的意思是以d元素开头的任意一个字符串,也就是说只要是以d开头的字符串,后面的元素不论是什么,都是符合规则的,总之必须要以d开头。
“.” 较为常用,其代表的意思是任意字符,其表示的范围非常广,可以接任意字符,不论是中英文,还是下划线之类的特殊字符,都是可以代表的。举个栗子,正则表达式“^d.”就是代表以d开头的字符串,b后边接任意字符都可以。
“*” 也十分常用,其代表的意思是前面的字符可以重复任意多遍,可以是0次,1次,2次等任意多次。
以下为第一个实例,匹配的正则表达式"^z.*" z开头的后面接任意多任意类型的字母数字字符
如上图所示,该正则表达式能够顺利匹配得到string中某部分。
“$” 代表的意思是结尾字符。举个栗子,正则表达式“3$”,表示匹配以3为结尾的字符串。代码演示如下图所示。
看以下示例,很好理解,两个正则表达式分别匹配0结尾和2结尾的实例,结果当然匹配不到2结尾的字符串。因为string结尾是0。
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。
非贪婪匹配:就是匹配到结果就好。
首先看一个‘贪婪’的例子:
在这次贪婪模式的匹配下,匹配的是 "yes" and i say "no",因为默认为贪婪匹配,所以选取了最长的部分。
其次观察一下如果是‘非贪婪’的例子。
显然,加入模式字符“?”之后,进入了非贪婪模式,而不会选取最长的那一段。
为了加深理解,再来看一个贪婪与非贪婪的实例。(\\d+表示单个以及多个数字)
看看这个贪婪例子,得到这个结果由于以下原因:
1.由于存在‘.*’则这一部分在贪婪模式下会在满足正则表达式的情况下让匹配的段最长
2. \\d+表示任意长度的数字组合(至少有一个数字)
所以为了满足1的贪婪条件,2的数字组合长度为1
而第二种情况下,在‘.’后加上‘?’使得前面这一段变的非贪婪(即匹配到满足条件的即可),所以当它们匹配到第一个数字1时,就结束‘.*’ 这一部分的匹配,开始‘\\d+’这一部分。
“{}”实质上也是一个限定词的用法,其限定前面字符所出现的次数,其常用的模式有三种,分别是“{数字}”、“{数字,}”和“{数字1, 数字2}”。举个例子,如“{1}”、“{1,}”和“{1, 3}”。
1.形式A 限定{}前字符数量
如下图所示,.{2}指定了两个之间有2个字符,所以不会匹配只有一个中间字符的‘pcp’,而且根据贪婪匹配原则,会选取前面‘.*’最长的匹配结果所以选择的是‘pbap’而不是‘pabp’,‘pcpp’
2.形式B “{1,}”代表的是前面的字符出现1次及以上;特殊字符“{2,}”代表的是前面的字符出现2次及以上;特殊字符“{3,}”代表的是前面的字符出现3次及以上;以此类推。举个栗子,如下图所示。
3.形式C “{2, 3}” 代表的是前面的字符至少出现2次,最多出现3次;
注意,这里采用了‘非贪婪’模式,所以出现第一个符合匹配正则表达式的部分之后,该p前面的部分将最短。
竖线“|”实质上是一个或的关系。并且当两个都满足时会优先匹配最前面的
还能够使用这种多层的匹配
为什么这里不是paa而是paap呢?因为match函数的规则。
也就是说re.match会从最左边开始匹配,并且要求必须在起始位置开始匹配。
那么这里的匹配可以理解为:paap14是在起始位置的,而paa14和起始位置paap14不符合(这里的起始不是指第一个,而是能从第一个字符向后匹配到某个字符,期间不断不少,个人理解)
正则表达式特殊符号是“[]”。中括号十分实用,其有特殊含义,其代表的意思是中括号中的字符只要满足其中任意一个就可以。
A. 匹配模式为[abcd],在这里正则表达式代表的意思是字符串第一个字符是abcd四个字符中的任意一个。
B. [0-9]代表是的是0到9中任意一数字
C. [a-z]代表26个英文小写字母;[A-Z]代表26个英文大写字母。
D. [^],在中括号中加入特殊字符“^”,表示非,取反的意思。举个栗子,“[^1]”的意思是字符不等于1。
还有一些用法,以下就不一一实例了
2.1 “\\s”与“\\S”
“\\s”代表的意思是匹配空格
\\s* 匹配多个空格
“\\S”代表的意思与“\\s”代表的意思刚刚相反,也就是说匹配的那个字符只要不是空格,都可以匹配。
2.2 [\\u4E00-\\u9FA5]
[\\u4E00-\\u9FA5]特殊字符是固定的写法,其代表的意思是汉字。换句话说,只要字符中是汉字,就可以通过该字符进行匹配,该特殊字符也是用中括号括起来的。
2.3 "\\w"与"\\W"
“\\w”代表的意思是该字符为任意字符,但是和特殊字符“.”的意思不同。
“\\w”代表的字符主要包括26个大写字母A到Z,即[A-Z]、26个小写字母a到z,即[a-z]、10个阿拉伯数字0到9,即[0-9]和下划线“_”。总结起来就是,“\\w”代表的意思是[A-Za-z0-9_]中任意一个字符。
“\\W”代表的意思与“\\w”刚刚相反,也就是匹配除了[A-Za-z0-9_]之外的其他字符。接上一步的例子,此时将“\\w”改为“\\W”。
对比:“.” 代表的意思是任意字符,其范围比“\\w”代表的意思要广。
用以上所学的正则表达式字符和模式实现一个简单的应用。
Demand feedback
