
Products
GG网络技术分享 2025-03-18 16:14 71
在用python处理excel时,想用正则表达式区分时间和价钱,字符串有如下几种类型:15.70元 2013-8 2017 228.00 1987.3 如下几种类型
我现在想要用正则表达式筛选出2013-8、2017、1987.3这个样子的数据,将其放到字典{‘出版时间’:''}字段,其余数字放入价钱字段
elif dataIndex == 0:i.find('.')
i.find('元')
i.find('HKD')
i.find('-')
dict_Two["出版社"] = dataStringOne
if i.find('.') != -1:
dict_Two["价格"] = dataStringTwo
elif i.find('元') != -1:
dict_Two["价格"] = dataStringTwo
elif i.find('HKD') != -1:
dict_Two["价格"] = dataStringTwo
elif i.find('-') != -1:
dict_Two["出版时间"] = dataStringTwo
else:
dict_Two["出版时间"] = dataStringTwo
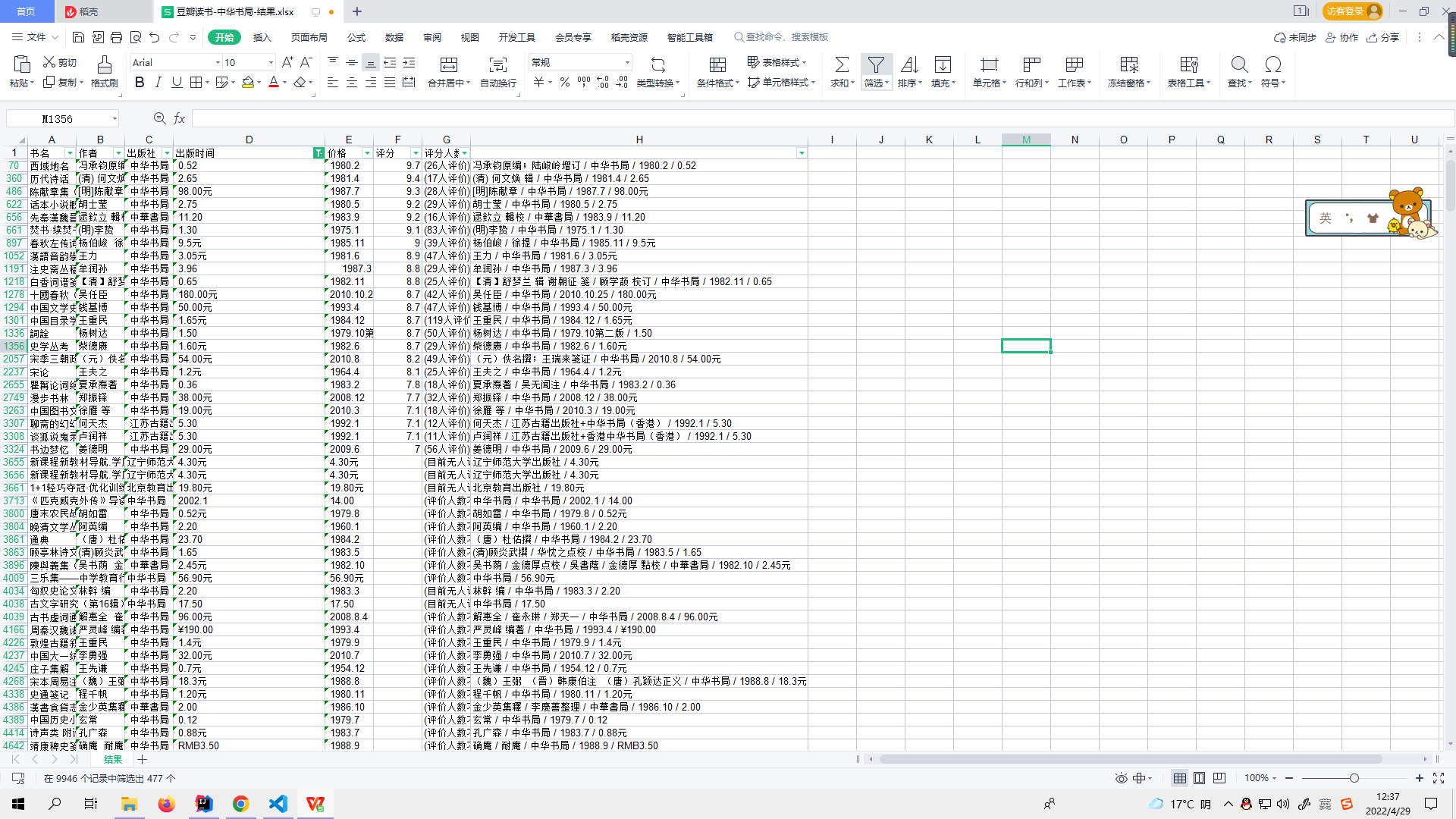
希望将2013-8、2017、1987.3这类型的数据筛选出来
题中年份后面表示日月最多6个字符,试试如下代码:
import res=['新书/20200412/价格22.6元','旧书1/2010.3/价格10.5元','旧书2/2008-3-5/价格8.8元','新书1/2021-05-06/价格30元','新书2/2022/价格50元','中华书局《月读》编辑部 编著']
res=[]
for x in s:
try:
res.append(re.findall('\\/(\\d{4}[-.\\d+]{0,6})\\/', x)[0])
except:
res.append('')
print(res)
F:\\2022\\py01>t11['20200412', '2010.3', '2008-3-5', '2021-05-06', '2022', '']
import re
z = '''
某人编撰;某人增订 / xx书局 / 1980.2 / 0.52
xxxx / xxx出版社 / 1981.4 / 2.65
xxxx / xxxx / 1983.9 /11.20
xxx / xxx / 1979.10第二版 / 1.50
xxxxx / 56.90
四库全书 / xxxxx / 2008.12 / 1045.5元
'''r = [re.findall('^(?=.*?((?<!\\d)(?:19|20)\\d{2}(?:[\\.-/]\\d{1,2}(?!\\d))?))?(?=.*?(?<!\\d)(?<!(?<!\\d)(?:19|20)\\d{2}\\.)(?!(?:19|20)\\d{2}(?!\\d))(\\d+(?:\\.\\d+)?))?',n) for n in re.findall('[^\\r\\n]+',z)]
print(r)
for i in r:
print('日期',i[0][0],'价格',i[0][1])
import rea = re.findall(r"[0-9]{4}[-.]?[0-9].*",str)
\\d{4}([-.]\\d{1,2}){0,2}
您好,我是有问必答小助手,您的问题已经有小伙伴帮您解答,感谢您对有问必答的支持与关注!这一节我们介绍一下分组匹配。
Demand feedback
