
Products
GG网络技术分享 2025-03-18 16:14 68
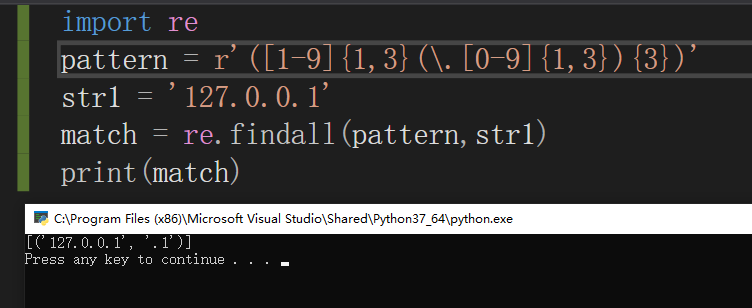
应该是这样进行匹配
import reip ='192.168.1.1'
trueIp =re.search(r'(([01]{0,1}\\d{0,1}\\d|2[0-4]\\d|25[0-5])\\.){3}([01]{0,1}\\d{0,1}\\d|2[0-4]\\d|25[0-5])',ip)
print(trueIp)
而findall这个函数
findall(string[, pos[, endpos]])是在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果没有找到匹配的,则返回空列表。
string : 待匹配的字符串。
pos : 可选参数,指定字符串的起始位置,默认为 0。
endpos : 可选参数,指定字符串的结束位置,默认为字符串的长度。
>>> str1 = '127.0.0.1 192.168.1.1 256.256.0.0'>>> pattern = re.compile(r"((?:(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d)\\.){3}(?:25[0-5]|2[0-4]\\d|[01]?\\d?\\d))")>>> pattern.findall(str1)['127.0.0.1', '192.168.1.1']
>>> 127.0.0.1
正则应该这样写,连续数组\\d+, 后面是有规律的.\\d+......, 重复需要用分组,由于分组用(),所以要强调非捕获组?:,
所以完整正则为:
import re
regex = r"\\d+(?:.\\d+)+"
test_str = ("127.0.0.1\\n"
"133.5.7.8")
regexp = re.compile(regex)
MT = regexp.findall(test_str)
print(MT)
------输出如下:
['127.0.0.1', '133.5.7.8']**
| 元字符 | 含义 |
|---|---|
| . | 匹配任意一个字符 |
| \\d | 一个数字 |
| \\w | 可以组成word的一个字母 |
| + | 次数>=1 |
| ? | 次数==1 |
| * | 次数>=0 |
例。下面是学校的介绍信息,其中包含了电话号码,利用正则表达式可以很容易从这些字符中提取电话号码。
Demand feedback
