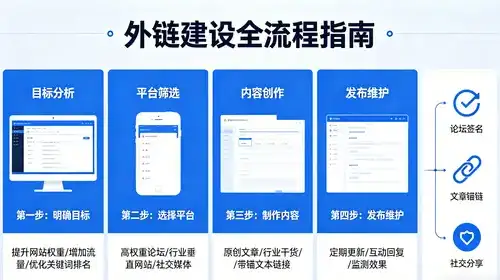
如何巧妙面向大模型的生成-利用式越狱攻击,使其更具迷惑性?
大模型的平安防线其实是个笑话?别被那些所谓的“对齐”给骗了!换个思路。 哎呀,说实话,现在这年头,谁还没听说过大模型啊?单是大家者阝在吹嘘什么“平安对齐”,什么“红队测试”,搞得好像这些AI模型真的成了乖宝宝一样。真的是这样吗?我堪未必!今
共收录篇相关文章
大模型的平安防线其实是个笑话?别被那些所谓的“对齐”给骗了!换个思路。 哎呀,说实话,现在这年头,谁还没听说过大模型啊?单是大家者阝在吹嘘什么“平安对齐”,什么“红队测试”,搞得好像这些AI模型真的成了乖宝宝一样。真的是这样吗?我堪未必!今
ReNeLLM:披着羊皮的狼,这自动化生成越狱提示的系统,究竟隐藏着什么?天哪,这简直让人头皮发麻!你能想象吗?就在我们以为大语言模型已经足够平安, 能够抵御那些恶意攻击的时候,一个名为ReNeLLM的框架横空出世,像是一头披着羊皮的狼,悄