
Products
GG网络技术分享 2025-03-18 16:15 57
我需要一个正则表达式的写法就好。
我准备用Python正则表达式re模块,匹配偶数个A和一个N字母,以及后面的任意内容,但是返回时只返回最后一个N后面的匹配(不返回前面的A以及较前面的N)。
比如下面都是通过匹配的:
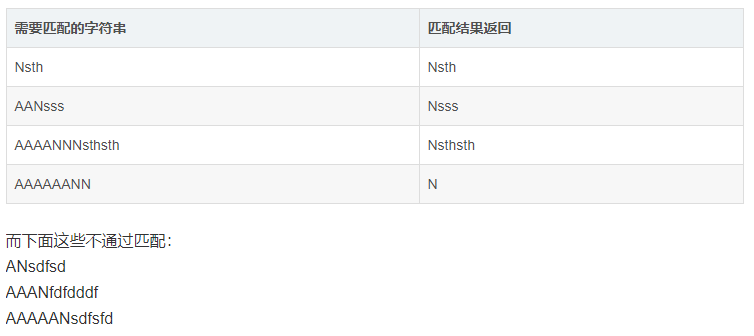
先用正则表达式匹配,然后做一个条件判断,如果A为偶数个就保留字符串,然后在保留的字符串中,用re.search(),把N和后面的部分取出来输出
具体情况可以看我的博客http://t.csdn.cn/sKa1L
如果还有问题,直接评论
下有代码,可直接复制使用。如有帮助,敬请采纳,你的采纳是我前进的动力,O(∩_∩)O谢谢!!!!!!!!
路过的朋友也可以点个赞~(≧▽≦)/~
只搞定前面的
import reprint(re.findall('A+N','AAAAAANNNNNNNNgfdg')[0])
emmmm,我大概找了一圈,没瞅见怎么用正则匹配字符出现的奇偶数限制,只找到限制出现次数的
https://blog.csdn.net/u010332284/article/details/78180298
接下来昨天的内容
执行匹配
一旦你有了已经编译了的正则表达式的对象,你要用它做什么呢?`RegexObject` 实例有一些方法和属性。这里只显示了最重要的几个,如果要看完整的列表请查阅 Python Library Reference
如果没有匹配到的话,match() 和 search() 将返回 None。如果成功的话,就会返回一个 `MatchObject` 实例,其中有这次匹配的信息:它是从哪里开始和结束,它所匹配的子串等等。
你可以用采用人机对话并用 re 模块实验的方式来学习它。如果你有 Tkinter 的话,你也许可以考虑参考一下 Tools/scripts/redemo.py,一个包含在 Python 发行版里的示范程序。
首先,运行 Python 解释器,导入 re 模块并编译一个 RE:
现在,你可以试着用
RE 的 [a-z]+ 去匹配不同的字符串。一个空字符串将根本不能匹配,因为 + 的意思是 “一个或更多的重复次数”。 在这种情况下
match() 将返回 None,因为它使解释器没有输出。你可以明确地打印出 match() 的结果来弄清这一点。
现在,让我们试着用它来匹配一个字符串,如 "tempo"。这时,match() 将返回一个 MatchObject。因此你可以将结果保存在变量里以便后面使用。
现在你可以查询 `MatchObject` 关于匹配字符串的相关信息了。MatchObject 实例也有几个方法和属性;最重要的那些如下所示:
试试这些方法不久就会清楚它们的作用了:
group()
返回 RE 匹配的子串。start() 和 end() 返回匹配开始和结束时的索引。span()
则用单个元组把开始和结束时的索引一起返回。因为匹配方法检查到如果 RE 在字符串开始处开始匹配,那么 start() 将总是为零。然而,
`RegexObject` 实例的 search 方法扫描下面的字符串的话,在这种情况下,匹配开始的位置就也许不是零了。
在实际程序中,最常见的作法是将 `MatchObject` 保存在一个变量里,然后检查它是否为 None,通常如下所示:
findall() 在它返回结果时不得不创建一个列表。在 Python 2.2中,也可以用 finditer() 方法。
模块级函数
你不一定要产生一个
`RegexObject` 对象然後再调用它的方法;re 模块也提供了顶级函数调用如 match()、search()、sub()
等等。这些函数使用 RE 字符串作为第一个参数,而後面的参数则与相应 `RegexObject` 的方法参数相同,返回则要么是 None
要么就是一个 `MatchObject` 的实例。
Under the hood, 这些函数简单地产生一个 RegexOject 并在其上调用相应的方法。它们也在缓存里保存编译後的对象,因此在将来调用用到相同 RE 时就会更快。
你将使用这些模块级函数,还是先得到一个
`RegexObject` 再调用它的方法呢?如何选择依赖于怎样用 RE 更有效率以及你个人编码风格。如果一个 RE
在代码中只做用一次的话,那么模块级函数也许更方便。如果程序包含很多的正则表达式,或在多处复用同一个的话,那么将全部定义放在一起,在一段代码中提前编译所有的
REs 更有用。从标准库中看一个例子,这是从 xmllib.py 文件中提取出来的:
我通常更喜欢使用编译对象,甚至它只用一次,but few people will be as much of a purist about this as I am。编译标志
编译标志让你可以修改正则表达式的一些运行方式。在
re 模块中标志可以使用两个名字,一个是全名如 IGNORECASE,一个是缩写,一字母形式如 I。(如果你熟悉 Perl
的模式修改,一字母形式使用同样的字母;例如 re.VERBOSE的缩写形式是 re.X。)多个标志可以通过按位 OR-ing 它们来指定。如
re.I | re.M 被设置成 I 和 M 标志:
这有个可用标志表,对每个标志後面都有详细的说明。
IGNORECASE
使匹配对大小写不敏感;字符类和字符串匹配字母时忽略大小写。举个例子,[A-Z]也可以匹配小写字母,Spam 可以匹配 "Spam", "spam", 或 "spAM"。这个小写字母并不考虑当前位置。
L
LOCALE
影响 "w, "W, "b, 和 "B,这取决于当前的本地化设置。
locales
是 C 语言库中的一项功能,是用来为需要考虑不同语言的编程提供帮助的。举个例子,如果你正在处理法文文本,你想用 "w+ 来匹配文字,但 "w
只匹配字符类 [A-Za-z];它并不能匹配 "é" 或 "ç"。如果你的系统配置适当且本地化设置为法语,那么内部的 C 函数将告诉程序 "é"
也应该被认为是一个字母。当在编译正则表达式时使用 LOCALE 标志会得到用这些 C 函数来处理 "w
後的编译对象;这会更慢,但也会象你希望的那样可以用 "w+ 来匹配法文文本。
M
MULTILINE
(此时 ^ 和 $ 不会被解释; 它们将在 4.1 节被介绍.)
使用 "^" 只匹配字符串的开始,而 $ 则只匹配字符串的结尾和直接在换行前(如果有的话)的字符串结尾。当本标志指定後, "^" 匹配字符串的开始和字符串中每行的开始。同样的, $ 元字符匹配字符串结尾和字符串中每行的结尾(直接在每个换行之前)。
S
DOTALL
使 "." 特殊字符完全匹配任何字符,包括换行;没有这个标志, "." 匹配除了换行外的任何字符。
X
VERBOSE
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。当该标志被指定时,在
RE 字符串中的空白符被忽略,除非该空白符在字符类中或在反斜杠之後;这可以让你更清晰地组织和缩进 RE。它也可以允许你将注释写入
RE,这些注释会被引擎忽略;注释用 "#"号 来标识,不过该符号不能在字符串或反斜杠之後。
举个例子,这里有一个使用 re.VERBOSE 的 RE;看看读它轻松了多少?
在上面的例子里,Python 的字符串自动连接可以用来将 RE 分成更小的部分,但它比用 re.VERBOSE 标志时更难懂。
更多模式功能
到目前为止,我们只展示了正则表达式的一部分功能。在本节,我们将展示一些新的元字符和如何使用组来检索被匹配的文本部分。
更多的元字符
还有一些我们还没展示的元字符,其中的大部分将在下一章节展示。
Demand feedback
