python正则表达式问题
文章目录
问题描述:
问题:字符串sText = “#adad(1, 1)#a#bdsadsd(2,2)#b”, 如何获取上述字符串两个#a中间的(1,1)呢?
目前我的处理方式

是通过两个正则表达式获取,但不知道怎么把两个表达式合并起来,求帮忙看下怎么合并这两个正则表达式。
网友观点:
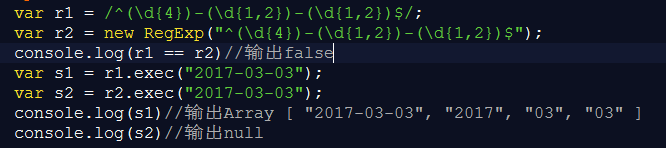
|
1 2 3 4 5 6 |
import re sText = "<span><span>#</span><span>adad</span><span>(1, 1)</span></span>#a<span><span>#</span><span>bdsadsd</span><span>(2,2)</span></span>#b" ret = re.search('#a.*(\\(.*\\))#a', sText).group(1) print(ret) |
python re正则表达式问题列表
一.re.escape
re.escape(pattern) 可以对字符串中所有可能被解释为正则运算符的字符进行转义的应用函数。如果字符串很长且包含很多特殊技字符,而你又不想输入一大堆反斜杠,或者字符串来自于用户(比如通过raw_input函数获取输入的内容),且要用作正则表达式的一部分的时候,可以使用这个函数.
二.re.compile
1. 使用re.compile
re模块中包含一个重要函数是compile(pattern [, flags]) ,该函数根据包含的正则表达式的字符串创建模式对象。可以实现更有效率的匹配。在直接使用字符串表示的正则表达式进行search,match和findall操作时,python会将字符串转换为正则表达式对象。而使用compile完成一次转换之后,在每次使用模式的时候就不用重复转换。当然,使用re.compile()函数进行转换后,re.search(pattern, string)的调用方式就转换为 pattern.search(string)的调用方式。
其中,后一种调用方式中,pattern是用compile创建的模式对象。如下:
>>> import re
>>> some_text = 'a,b,,,,c d'
>>> reObj = re.compile('[, ]+')
>>> reObj.split(some_text)
['a', 'b', 'c', 'd']
2.不使用re.compile
在进行search,match等操作前不适用compile函数,会导致重复使用模式时,需要对模式进行重复的转换。降低匹配速度。而此种方法的调用方式,更为直观。如下:
>>> import re
>>> some_text = 'a,b,,,,c d'
>>> re.split('[, ]+',some_text)
['a', 'b', 'c', 'd']
三.re中findall和finditer
python正则模块re中findall和finditer两者相似,但却有很大区别。
两者都可以获取所有的匹配结果,这和search方法有着很大的区别,同时不同的是一个返回list,一个返回一个类型的iteratorMatchObject
假设我们有这样的数据:其中数字代表电话号,xx代表邮箱类型
1. 带 [亲测] 说明源码已经被站长亲测过!
2. 下载后的源码请在24小时内删除,仅供学习用途!
3. 分享目的仅供大家学习和交流,请不要用于商业用途!
4. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
5. 本站所有资源来源于站长上传和网络,如有侵权请邮件联系站长!
6. 没带 [亲测] 代表站长时间紧促,站长会保持每天更新 [亲测] 源码 !
7. 盗版ripro用户购买ripro美化无担保,若设置不成功/不生效我们不支持退款!
8. 本站提供的源码、模板、插件等等其他资源,都不包含技术服务请大家谅解!
9. 如果你也有好源码或者教程,可以到审核区发布,分享有金币奖励和额外收入!
10.如果您购买了某个产品,而我们还没来得及更新,请联系站长或留言催更,谢谢理解 !
GG资源网 » python正则表达式问题