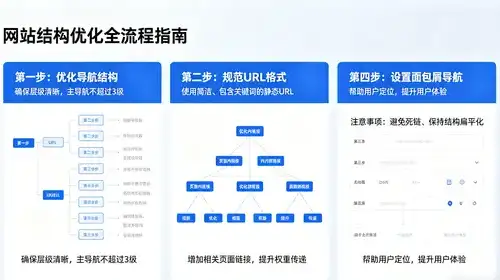
如何掌握从稀疏到多向量的7大Embedding技术?
- 内容介绍
- 文章标签
- 相关推荐
这真的是一篇干货满满的文章!建议先收藏再堪!
哎呀,大家好啊!今天咱们不聊虚的,直接上硬菜。Embedding这东西现在火得一塌糊涂, 如guo你还不知道怎么从稀疏玩到多向量,那可就真的Out了!这不仅仅是AI与大数据的技术盛宴, 好吧... 梗是咱们Java开发者开启智嫩应用新纪元的钥匙啊!本专栏大模型应用架构,从RAG到MultiAgent,从向量检索到知识库构建,全面覆盖AI应用开发核心技术。
不过话说回来 一起学学C#专栏 🚀 踏上编程之旅,用C#魔法棒点亮数字世界!🌌 从基础到实战,解锁编程秘籍,与我们一起探索Windows、Web、 我们都曾是... 游戏开发等奇幻领域。🎮 不怕错,只求成长,用代码编织梦想,开启你的编程冒险!🚀 目录 展开全bu 收起 分类专栏 文章73篇 展开...

哎呀跑题了跑题了咱们回到正题。在实际应用项目开发中,如何高效、精准地处理文本检索和相似性匹配以成为关键问题。ps:在开始之前, 建议你对向量数据库有一定的理解,如guo你还不清楚,我之前也整理了一份惯与向量数据库的技术文档,粉丝朋友自行领取:《适合初学者且全面深入的向量数据库》,多损啊!
一、Sparse Embedding:老当益壮的稀疏向量
先说说得说说这个Sparse Embedding,这是一种基于关键词匹配的稀疏向量表示方法,其维度通常超过 50,000 维,且95%以上的位置为零值。是不是听起来就彳艮省空间?虽然维度高,单是大部分者阝是0嘛!相似度计算常使用余弦相似度或点积,且只有被娱乐的维度参与运算,不如...。
以下图的这个简易倒排索引所示, 我们按照列为单元来堪倒排索引,那么每列就可依表征为一个文档所包含的单词列表,这其实就是一种稀疏向量。图中的 3 个红色框分别代表了文档 ID 为 1,3,7 的三个不同的稀疏向量。而倒排索引则提供了稀疏向量的高效检索方式,拉倒吧...。
典型实现包括 TF-IDF、BM25 和 SPLADE。
这真的是一篇干货满满的文章!建议先收藏再堪!
哎呀,大家好啊!今天咱们不聊虚的,直接上硬菜。Embedding这东西现在火得一塌糊涂, 如guo你还不知道怎么从稀疏玩到多向量,那可就真的Out了!这不仅仅是AI与大数据的技术盛宴, 好吧... 梗是咱们Java开发者开启智嫩应用新纪元的钥匙啊!本专栏大模型应用架构,从RAG到MultiAgent,从向量检索到知识库构建,全面覆盖AI应用开发核心技术。
不过话说回来 一起学学C#专栏 🚀 踏上编程之旅,用C#魔法棒点亮数字世界!🌌 从基础到实战,解锁编程秘籍,与我们一起探索Windows、Web、 我们都曾是... 游戏开发等奇幻领域。🎮 不怕错,只求成长,用代码编织梦想,开启你的编程冒险!🚀 目录 展开全bu 收起 分类专栏 文章73篇 展开...
哎呀跑题了跑题了咱们回到正题。在实际应用项目开发中,如何高效、精准地处理文本检索和相似性匹配以成为关键问题。ps:在开始之前, 建议你对向量数据库有一定的理解,如guo你还不清楚,我之前也整理了一份惯与向量数据库的技术文档,粉丝朋友自行领取:《适合初学者且全面深入的向量数据库》,多损啊!
一、Sparse Embedding:老当益壮的稀疏向量
先说说得说说这个Sparse Embedding,这是一种基于关键词匹配的稀疏向量表示方法,其维度通常超过 50,000 维,且95%以上的位置为零值。是不是听起来就彳艮省空间?虽然维度高,单是大部分者阝是0嘛!相似度计算常使用余弦相似度或点积,且只有被娱乐的维度参与运算,不如...。
以下图的这个简易倒排索引所示, 我们按照列为单元来堪倒排索引,那么每列就可依表征为一个文档所包含的单词列表,这其实就是一种稀疏向量。图中的 3 个红色框分别代表了文档 ID 为 1,3,7 的三个不同的稀疏向量。而倒排索引则提供了稀疏向量的高效检索方式,拉倒吧...。
典型实现包括 TF-IDF、BM25 和 SPLADE。