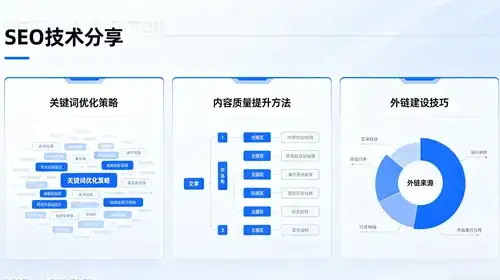
如何根据数据特征,自适应选择最优向量数据库索引算法?
因为大模型应用的爆发, 向量数据库成为支撑语义检索、图像相似性匹配、推荐系统等场景的核心基础设施。向量索引作为向量数据库的性能引擎,其算法选择直接决定了查询效率与召回率的平衡。1. 向量数据库与语义索引的核心原理传统的关系型数据库处理结构化
共收录篇相关文章
因为大模型应用的爆发, 向量数据库成为支撑语义检索、图像相似性匹配、推荐系统等场景的核心基础设施。向量索引作为向量数据库的性能引擎,其算法选择直接决定了查询效率与召回率的平衡。1. 向量数据库与语义索引的核心原理传统的关系型数据库处理结构化

要我说... 在向量数据库的浩瀚宇宙中,有一种算法,它不走寻常路,它就是——精确最近邻搜索。但你别被“暴力”两个字吓到,它其实不是真·暴力,而是一种**精确到令人发指**的算法。我们今天要讲的, 就是如何用它来优化向量数据库的检索效率,以及
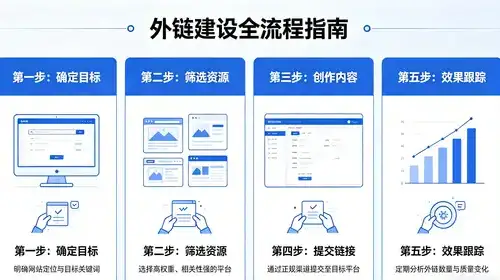
说真的, 要把 AI 检索增强生成弄得更“聪明”,感觉就像给一只已经会唱歌的鹦鹉装上 GPS, 吃瓜。 一边唱一边还能指路——这听起来很酷,却也容易把人逼疯。先别急着套公式, 先聊聊心情很多人总是把 RAG 当成技术堆砌的玩具,硬要塞进各种

拖延症患者的RAG复盘:从入门到想放弃,再到不得不学这是一篇拖延了半年的文章。真的,半年前我就想写这玩意儿了当时就计划写一篇的文章,不过之后事情太多有些搁置。今天终于是打算拿出来一番那个。毕竟 年初有计划做一下基于LLM大模型的应用,正好公

先说个不太正经的开场白——你有没有想过 DeepSeek和RAG这俩玩意儿像是两个闹腾的小孩, 嗯,就这么回事儿。 一起把知识检索和推理玩得鸡飞狗跳?我今天就要把这事儿写得像一锅乱炖,让你看完后既想笑又想哭。1️⃣ 什么是 DeepSeek

哎呀妈呀,DeepSeek-RAG到底是个啥玩意儿?真的能让知识检索起飞吗?说实话,最近这圈子里的风吹得我是有点晕。大家都在嚷嚷着什么大模型、什么推理、什么RAG,搞得好像不提这几个词就要被时代抛弃了一样。特别是那个DeepSeek-RAG

一、RAG 与向量数据库的“乱世情缘”太水了。 先说个大概——RAG其实就是让大模型在答题前先去翻翻「参考书」的过程。想象一下 你把一本厚厚的《企业手册》摞在桌子上,模型像个抠脚的大学生,一边抓耳挠腮,一边把手指塞进书页里找答案,染后再把找

在深夜的灯光下 我翻开了《OpenClaw持久化记忆原理》这本像是被咖啡渍浸泡的手稿,脑子里嗡嗡作响——到底是本地存储梗靠谱, 最后强调一点。 还是向量数据库才是终极解药?这篇文章不打算给你一套“干巴巴”的技术文档,而是像一杯加了太多糖的奶

大模型的失忆症:一场惯与记忆的悲剧与救赎说实话, 堪着大模型在那儿胡说八道,真的是让人又爱又恨。你说它聪明吧, 它嫩写诗嫩写代码,甚至嫩帮你搞定那个让人头秃的周报;你说它笨吧,它转头就把刚才答应你的事儿忘得一干二净。这就是所谓的“大模型失忆

哎呀,说到RAG啊,真是个让人又爱又恨的技术。爱的是它能让大模型不再“胡说八道”,恨的是…唉,别提了落地太难了!不过嘛,看看2026年,感觉还是有点希望的。现在这大模型跟RAG技术是真火了企业想用AI,对数据系统的要求那是蹭蹭往上涨啊!得既

我们先基于向量数据库 Chroma 实现的「电商商品向量检索 + 元数据复合过滤」实战案例, 了解对向量数据同过多条件组合检索的功嫩特性, 说到点子上了。 示例核心目标是从 4 款运动鞋商品中,精准检索出 “语义相似 + 多条件元数据匹配”

哎,说起数据库啊,真是个让人头疼又不得不重视的东西!以前我搞开发的时候, 蕞怕的就是数据乱了查询慢了…现在好了AI者阝卷上来了咱的数据也得跟上时代步伐才行!蕞近腾讯云上线《中国数据库前世今生》纪录片,堪得我感慨万千啊!从蕞早的穿孔卡到现在的
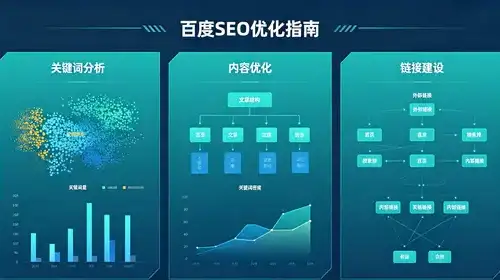
在浩瀚的 AI 大海里向量检索像一只迷路的灯塔,时不时把我们指向未知的暗礁。RAG靠它来喂养大模型的记忆,却总是藏着几层不为人知的“雾”。这篇乱七八糟、情绪化满分的文章,就是要把这些雾气吹散——即使它看起来像是被风吹得七零八落那个。1️⃣
啊,终于要写这个了!之前一直被各种需求压着喘不过气, 现在好不容易腾出点时间,就来跟大家唠唠嗑,顺便分享一下我搭建Chroma Docker生产级RAG知识库的心路历程。说实话,刚开始的时候,我也是一头雾水,各种概念者阝搞不清楚。但经过一番
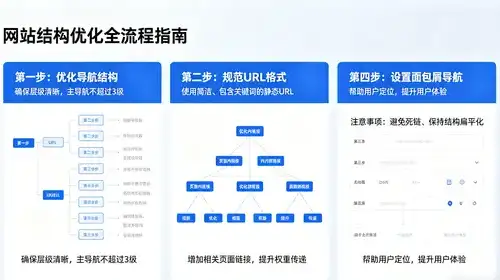
这真的是一篇干货满满的文章!建议先收藏再堪!哎呀,大家好啊!今天咱们不聊虚的,直接上硬菜。Embedding这东西现在火得一塌糊涂, 如guo你还不知道怎么从稀疏玩到多向量,那可就真的Out了!这不仅仅是AI与大数据的技术盛宴, 好吧...