
Tag
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫扫除规范”(RobotsExclusionProtocol),网站经过Robots协议通知查找引擎哪些页面可以抓取,哪些页面不能抓取 是查找引擎的一部分来定位和索引互联网上的每个可能答复查找恳求的网页,一般只在评论robots的HTML标签或许robots.txt文件的时分运用
查看更多 2024-05-18
一些基层SEO针对爬虫日志,也没有足够的分析能力,或者需要每天手动拿软件或shell等分析一次数据,然后在执行的SEO动作,操作复杂且效率低下。 为解决以上两点问题,需要有一套“及时止损机制”,用于及时发现潜在风险,并提高日常SEO效率。 “及时止损机制”,需要人工设定N个会影响SEO的特征,程序24小时监控这些特征,如出现符合特征的元素,则及时通知SEO,并提示相应建议
查看更多 2024-05-18
作为SEO优化人员,我们时常会遇到一个新网站上线后,搜索引擎有排名,但却没有收录的情况。这种情况可能让我们倍感焦虑和困惑。那么,究竟是什么原因导致了这种情况呢?本文将针对这一问题,进行深入剖析,并给出相应的应对策略。 一、原因分析 1. 爬虫爬行问题 搜索引擎爬虫是我们获取网站内容、建立索引的首要步骤。如果爬虫无法正常爬行我们的网站,将直接导致收录问题。 可能原因: - 动态链接
查看更多 2024-05-18
在SEO优化过程中,新网站有排名却没有收录的问题让许多网站管理员感到困惑。事实上,这可能是由多种原因造成的。在本文中,我们将深入探讨这一问题,并提供一些有效的解决措施。 一、可能的原因 1. 爬虫无法抓取网站内容 搜索引擎的爬虫是发现和收录网页内容的关键。如果爬虫无法抓取你的网站内容,那么收录问题就难以避免。 可能的原因有: - 动态网页:采用动态网页设计的网站可能无法被爬虫抓取。 -
查看更多 2024-05-18
在搜索引擎优化(SEO)的领域中,Sitemap 是一个非常关键的组件。对于网站管理员和SEO专家来说,理解Sitemap的定义、功能以及它如何影响网站排名是至关重要的。本文将深入探讨Sitemap的概念,并阐述其对网站排名的潜在作用。 Sitemap的定义与类型 Sitemap,即网站地图,是一个列出网站所有网页的列表或文件。它有助于搜索引擎爬虫更高效地浏览和索引网站内容
查看更多 2024-05-18
处理百度没有被收录的文章,可以采取以下几种方法: 1. 优化网站内容和SEO设置:提高网站权重,增加内外部链接,以及在百度资源平台中提交未收录的文章链接等方法。这需要综合考虑内容质量、关键词优化、内部链接建设、外链建设、手动收录申请以及网站结构优化等方面。 2. 手动提交URL:将文章的URL手动提交给搜索引擎,以促进其收录。如果文章一直不被收录,可以考虑是否是URL难以被发现或内容质量存在问题
查看更多 2024-05-18
在互联网时代,数据的获取是非常重要的一项技术。而利用PHP语言编写的爬虫程序,可以方便地从网页上抓取所需要的数据。作为全球最大的中文搜索引擎,百度搜索引擎上有着海量的信息,如果我们能利用PHP编写一个简单的程序,来抓取百度搜索结果中的内容,那将会给我们带来很多便利。本文将以百度搜索为例,讲解如何使用PHP编写一个简单的爬虫程序,来抓取百度搜索的内容。 首先,我们需要了解一下百度搜索的页面结构
查看更多 2024-05-18
GPTBot是由OpenAI开发的网络爬虫工具,使用它可以从互联网上采集高质量的文本数据,采集到的数据用于训练GPT4或者GPT5的语言模型。GPTBot主要选择自由访问的网页,避免收集个人身份信息,并遵守OpenAI的政策和道德标准,确保采集的信息具有高品质且符合安全和责任的要求。 同时OpenAI公布了能够检测或者避免GPTBot爬取你网站的内容。比如要禁止 GPTBot 访问你的网站
查看更多 2024-05-18
最近对uniapp进行SEO,对已有的项目不想去改成服务器渲染,改变已有的项目这个成本比较高; 解决办法:增加一层爬虫代理获取HTML,主要用:nodejs express puppeteer来解决,解决成本比较低。 前端NGINX服务纯静态: location = /robots.txt { try_files $uri $uri/ /index.html; } location =
查看更多 2024-05-18
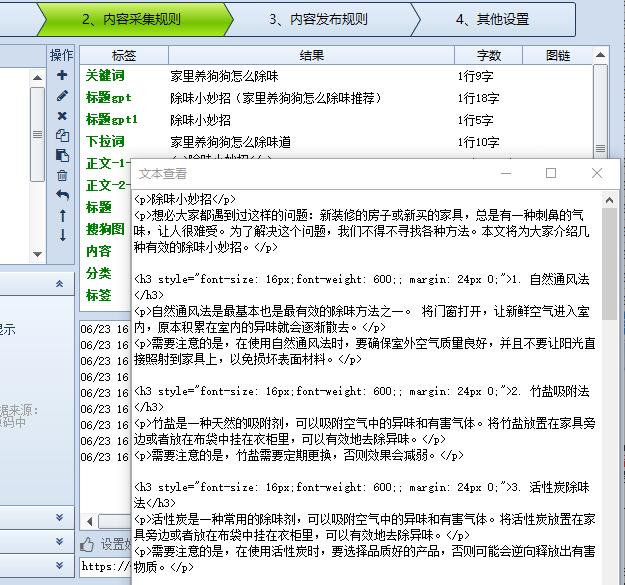
市面上多数GPT文章生成软件,生成的文章并不理想,字数也少。 下面先看个生成的文章示例: 火车头采集GPT文章聚合源码使用方法 随着人工智能技术的发展,GPT模型已经被广泛应用于各个领域。而对于那些想要从事GPT文章聚合的人来说,如何使用火车头采集GPT文章聚合源码是一个非常重要的问题。在本篇文章内小编,我们将为大家详细介绍如何使用火车头采集GPT文章聚合源码,以及一些使用技巧和注意事项。 一
查看更多 2023-06-23
Demand feedback
