
Products
GG网络技术分享 2025-03-18 16:14 68
给国外的前端页面对应的配置文件里面写了个脏话列表,
今天发现有的单词不能够成功匹配成脏话,
后面测试了一些数据,发现这些单词有些共同点就是单词最后一个位置上有特殊的字符,
例如:
cipką
cipkę
dojebać
dojebał
dojebię
dopieprzać
当这些字符 ą ę ć ł在单词中间时,可以匹配成脏话,例如zajebała能够成功识别成脏话,但是上述这种就不行
正则表达式如下:^((?!\\b(chuj|chuja|zesrywać|zesrywća)\\b)(\\s|\\S))*$
第一次:
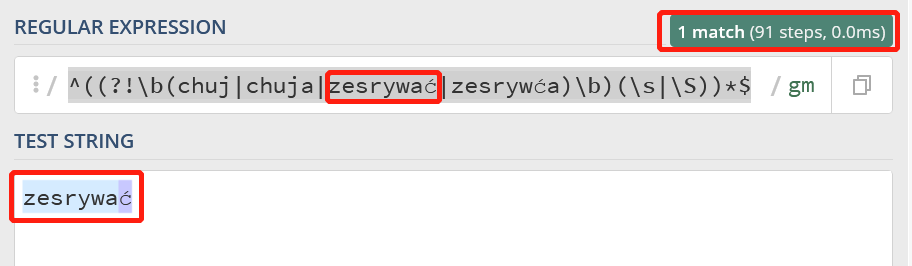
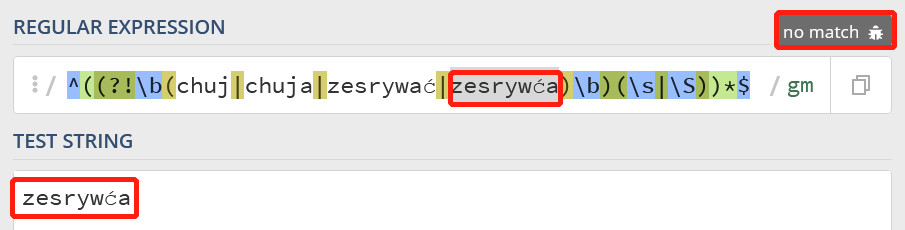
\\b 只能识别英文单词边界,其他语言的单词边界是无法识别的
貌似应该用哈希表啊?
有些地方叫字典。
在字典里的词是脏话,所以,需要先词法分析,把输入串分解成一个个单词,再把单词去字典里找。
词法分析用正则表达式完成即可。
欢迎新同学的光临
... ...
人若无名,便可专心练剑
我不是一条咸鱼,而是一条死鱼啊!
CSDN文章地址:[车联网安全自学篇] 四. 威胁检测之正则表达式手册教程【小抄】
关于正则表达式,很多人认为,使用的时候查询下就行,没必要深入学习,但是知识与应用永远都是螺旋辩证的关系,有需要查询也无可厚非,但是先掌握知识,可以让应用更创新,更深入,超越他人,必须要先掌握大量的深刻的知识。
但是学习正则并非易事:知识点琐碎、记忆点多、符号乱,难记忆、难描述、广而深且,说了那么多,开始正文吧
正则表达式又称规则表达式,计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本,是对字符串操作的一种逻辑公式,是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式使用一种符号系统,允许以最小的努力匹配复杂的文本模式。虽然对于正则表达式的语法没有正式的标准化,但是对于语法的基本元素有一个普遍的共识
正则表达式是处理字符串的强大工具,它有自己特定的语法结构,有了它,实现字符串的检索、替换、匹配验证、在HTML里提取想要的信息都是简简单单的事
例如,Windows下用于文件查找的通配符(wildcard),也就是*和?。如果想查找某个目录下的所有的Word文档的话,搜索*.doc。在Windows这里,*会被解释成任意的字符串。和通配符类似,正则表达式也是用来进行文本匹配的工具,只不过比起通配符,它能更精确地描述你的需求
Demand feedback
