
Products
GG网络技术分享 2025-03-18 16:14 46
正则表达式去提取网页标题内容,为什么会报错, 跟着B站上面的教程一模一样写的, 到底哪里错了, 我找不到原因, 请大家告诉我原因和思路;
只知道是【title = re.findall('"title":"(.*?)","pubdate"',response.text)[0]】这一行错了
请问如何更改才能提取到我想要的标题(还是用正则表达式),谢谢各位!!
import requests
import re
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
url='https://www.bilibili.com/video/BV19F411c74i'
response=requests.get(url=url,headers=headers)
print(response.text)
title = re.findall('"title":"(.*?)","pubdate"',response.text)[0]
print(title)
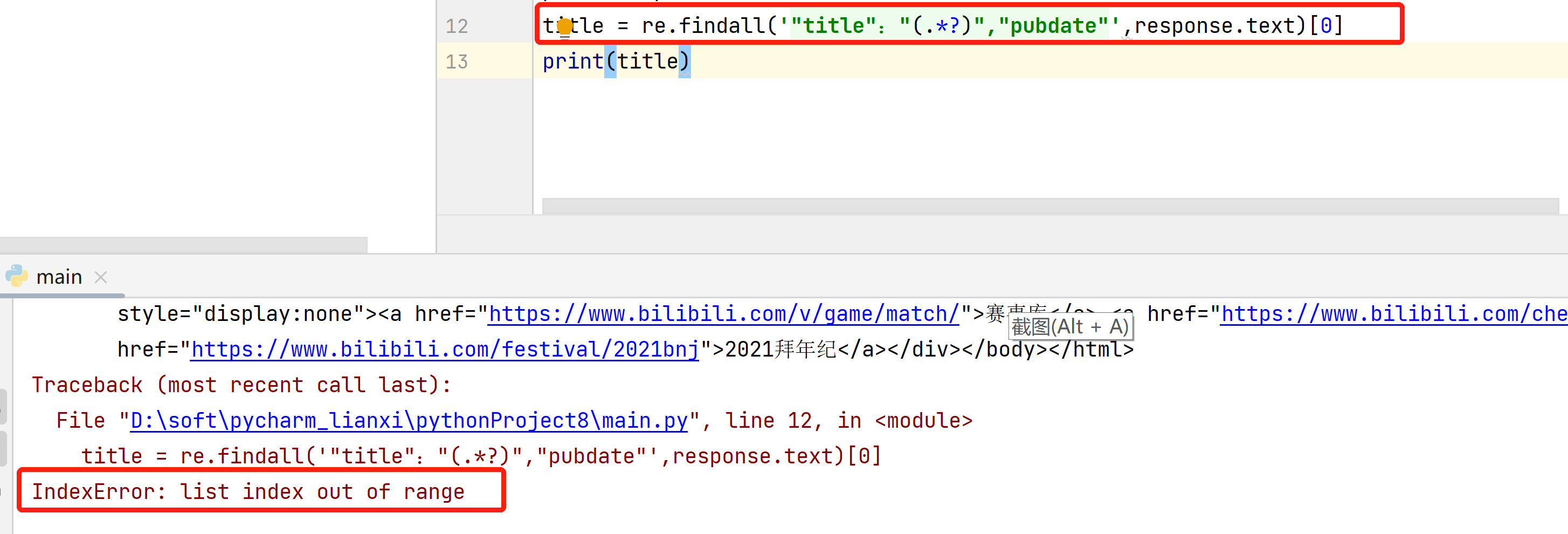
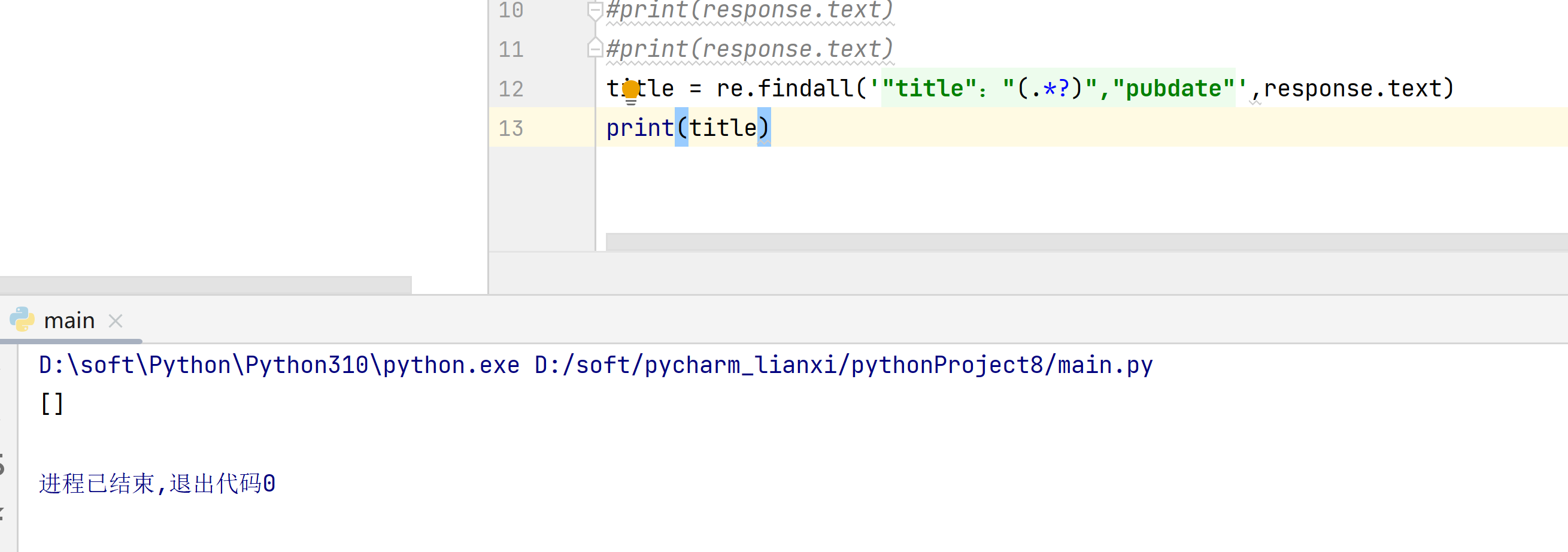
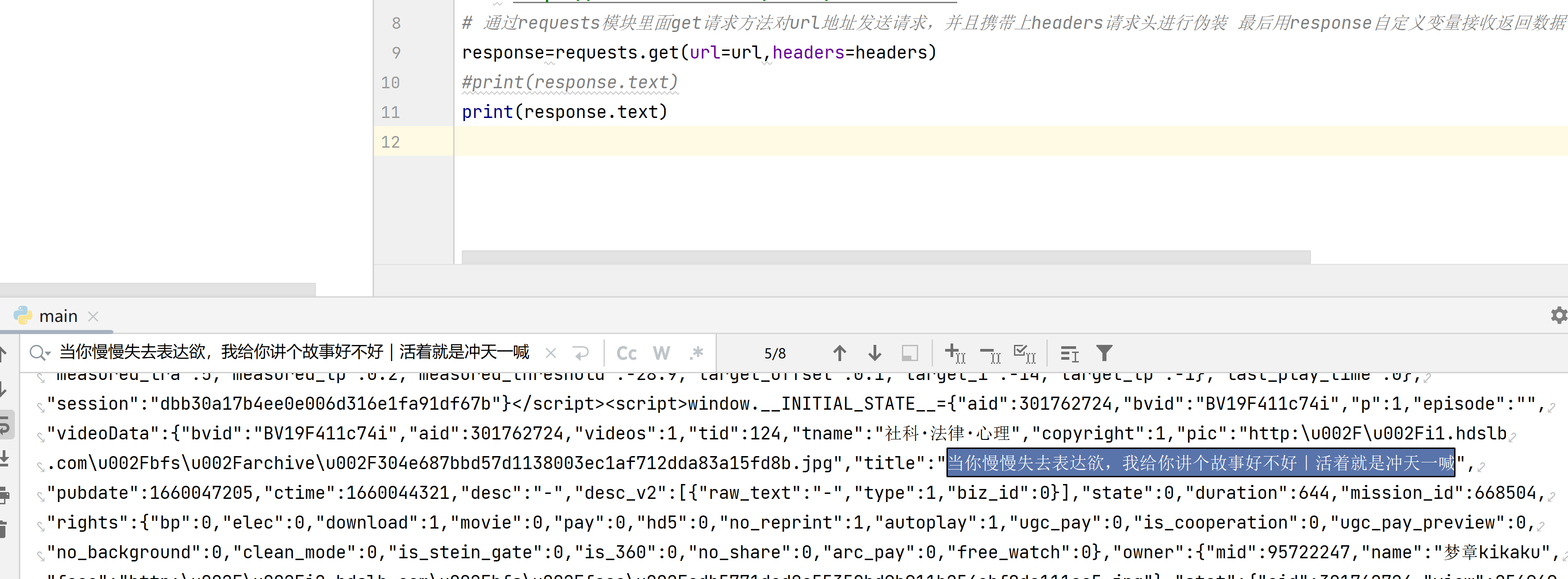
这个是正则没有匹配到结果,返回了空列表,空列表没有[0]下标的元素,所以报错,
因为response.text中并没有符合你写的正则条件,所以匹配结果为空列表,空列表加[0]的话就会报错,可以检查一下,response.text内容,然后再确认一下正则表达式是否有结果
这是你的正则表达式没有爬取到相应内容导致的,建议去掉末尾的[0]直接打印出来看看
网站变了,之前的教程不适用了
正则没有匹配到任何内容也就是空列表,正常用正则匹配带得都是非空得列表,空列表引用[0]表示取第一个元素,但是空列表没有元素所以报错说超出列表索引,你把代码贴出来帮你改改正则表达式
网页源代码可能变了
网站源代码改变,之前的代码失效
说明response.text里面是空值 网站可能有反爬虫手段 加点请求头user-agent和cookie试一下 如果还不行说明需要带data参数 还不行说明data里面可能有加密数据 没办法爬
这几天,一个朋友问我他在合并TCGA的mRNA数据和TMB(肿瘤突变负荷的数据)的数据的时候,遇到了一个问题,为什么下面这个正则表达式没办法获取正确的结果呢?
初看这个正则表达式感觉还真没啥问题,带着这个疑问让我们开启正则表达式的探索之旅。
看完本文之后,你就会知道为什么这个不对,以及怎么写对的,进而写更简单的对的写法。
正规表达式,又称正规表示式、正规表示法、规则表达式,英文全称Regular Expression,是计算机这个学科的一个概念。正规表达式通过单个字符串来描述、匹配一系列符合某个正则表达式规则的字符串。
在很多文本编辑器里,正规表达式通常被用来检索、替换那些符合某个模式的文本,包括常见的Rstudio、Visual studio code、Sublime、Editor、Pycharm等,在平常我们处理任何文本数据的时候,也会通过正则表达式来筛选我们想要的数据,尤其是在爬虫中,其实各种爬虫解析网页的包都是对正则表达式的进一步优化封装,所以掌握正则表达式对于希望能快速处理数据的我们是一项必不可少的技能。
正则表达式不仅有在线的网站可以帮助我们可视化审查我们的作者表达式是否正确,包括
https://tool.oschina.net/regex 、
https://c.runoob.com/front-end/854、
https://tool.chinaz.com/regex,
也有很多包来简化我们写正则表达式的过程,比如R语言中的stringr包,python语言中的re库,java内置的Pattern类。这里我们主要介绍R语言的string包。
R语言的stringr包是由大名鼎鼎的Hadley Wickham开发,是对于stringi的进一步封装。这个人有多牛,因为他数据处理和可视化开发工具方面的突出贡献,获得专为统计计算而设立的约翰·钱伯斯奖,这在当年可是让一众统计学家大呼不满。
Hadley Wickham通过开发ggplot2包让人们意识到原来R语言绘图可以这么简单美观,这可是为R语言争取了不少用户,因为觉得在数据处理不够便捷,大神就写了一个目前堪称数据处理的神器tidyverse,将众多的方法串联到一起,tidyverse是他把自己所写的包整理成了一整套数据处理的方法,包括ggplot2、readr、purrr、dplyr、tidyr、stringr、forcats、reshape2等。同时还专门写了一本书《R for Data Science》,中文书名是《R数据科学》。这本书里面也详细介绍了tidyverse的使用方法。这个大佬目前是Rstudio首席科学家,中国R语言的荣光谢益辉大神也在这个公司工作。
stringr包安装
我们先介绍下这个包的安装,第一种方法是从CRAN上安装发行版:install.packages("stringr"),另外一种是从github上安装最新的版本,可测试最新的功能, install.packages("devtools");devtools::install_github("tidyverse/stringr")
函数归类介绍
在介绍TCGA和stringr的使用之前,我们还是需要对这个包里面的函数做一个归类介绍,因为实在是太多高度集成化的函数,初看的时候很容易混淆。这里面的函数主要分为6大类,包括字符串匹配函数、字符串截取函数、字符串长度控制函数、字符串变化函数、字符串拼接函数、字符串排序函数。
字符串匹配函数
有str_detect、str_which、str_count、str_locate、str_locate_all。
str_detect可以检测pattern是否包括在某个字符串
str_count是str_detect的一个变种,它不是简单的返回TRUE和FALSE,它可以告诉你有多少个匹配上了
str_which告诉匹配的索引位置
str_locate和str_locate_all告诉匹配的开始和终止位置
字符串截取函数
包括str_sub、str_subset、str_extract、str_extract_all、str_match。
str_match_all str_sub在给定起始和终止参数的基础上对字符串进行截取,这个在我们确认字符串的结构是固定的时候用这个函数会大大简化我们的操作
str_subset用于截取匹配pattern的字符串
str_extract和str_extract_all用于从字符串中提取匹配字符,一个返回第一个,一个返回所有,并且有个参数simplify控制返回值类型,
TRUE返回matrix,FALSE返回字符串向量,str_match和str_match_all以矩阵形式返回匹配结果
字符串长度控制函数
包括str_length、str_pad、str_trunc、str_trim
str_length就是计算字符串的长度
str_pad(string, width, side = c("left", "right", "both"), pad = " ")这个函数width控制我们要填充后的长度,side表示填充方向,pad就是我们要填充什么进去,但是只能指定单个的字符
str_trim去除字符串的空白部分,可选择"both", "left", "right",默认选择both
str_trunc可以把字符串切割到指定长度
字符串变化函数
包括str_replace、str_replace_all、str_to_lower、str_to_upper
str_replace(string, pattern, replacement),
string: 字符串,字符串向量,
pattern: 匹配字符,
replacement: 用于替换的字符
我们需要记住参数的顺序,str_replace_all是替换所有匹配到的
str_to_lower、str_to_upper一个是转小写,一个是转大写
字符串拼接函数
包括str_c和str_dup。
str_c就是拼接多个字符串的
str_c(..., sep = "", collapse = NULL)
sep: 把多个字符串拼接为一个大的字符串,用于字符串的分割符,
collapse: 把多个向量参数拼接为一个大的字符串,用于字符串的分割符。
str_dup是为了复制字符串
字符串排序函数
包括str_sort和str_order。
str_order(x, decreasing = FALSE, na_last = TRUE, locale = "", ...),
str_sort(x, decreasing = FALSE, na_last = TRUE, locale = "", ...)。
x:需要排序的字符向量;
decreasing:排序方式,默认为升序;
na_last:是否将缺失值置于末尾,也可以删除NA,默认为TRUE;
str_order和str_sort的区别在于前者返回排序后的索引(下标),后者返回排序后的实际值
回到问题
我们再回到我们最开始的问题,那个为什么是错的,我们首先要知道 ? 是一个非贪婪匹配的意思。
贪婪匹配:正则表达式去匹配时,会尽量多的匹配符合条件的内容。标识符是+,?,*,{n},{n,},{n,m}匹配时,如果遇到上述标识符,代表是贪婪匹配,会尽可能多的去匹配内容
非贪婪匹配:正则表达式去匹配时,会尽量少的匹配符合条件的内容,一旦发现匹配符合要求,立即就匹配成功,而不会继续匹配下去(除非有全局匹配符g,开始下一组匹配)。标识符是+?,??,*?,{n}?,{n,}?,{n,m}? 。可以看到,非贪婪模式的标识符很有规律,就是贪婪模式的标识符后面加上一个?
在这我们呢在解释下这个截图的注释部分我们详细的解释了为什么错了。
就是因为最后的(.*?)的非贪婪匹配一个字符都不会匹配,是匹配的空字符,所以01A这部分字符就不会被替换,所以最后统一贴到了字符串的最后一部分。
所以我们可以通过 $来限制我们一定要匹配到最后一个字符,所以01A就不会被忽略了。
当然我们也可以去除 非贪婪符号 ? ,这样变为贪婪匹配了,还是可以匹配到最后的了。我们也可以通过stringr这个正则表达式的包的str_extract来提取匹配pattern字符。
本文首发于“ 挑圈联靠”微信公众号
转载请注明:解螺旋·临床医生科研成长平台。
Demand feedback
